Keyword [Pooling Indices] [SegNet]
Badrinarayanan V, Kendall A, Cipolla R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation[J]. IEEE transactions on pattern analysis and machine intelligence, 2017, 39(12): 2481-2495.
1. Overview
1.1. Motivation
- Due to the lack the good encoding techniques (poor ability to delineate boundaries), existing method use CRF to increase accuracy
In this paper. it proposed SegNet
- In decoder, using upsampling according to the pooling indices of the encoder’s corresponding max-pooling layer.

- Upsample. get sparse feature map
Conv. get dense feature map

Eliminate the need for learning to upsample
- Less memory in the inference time

1.2. Comparison
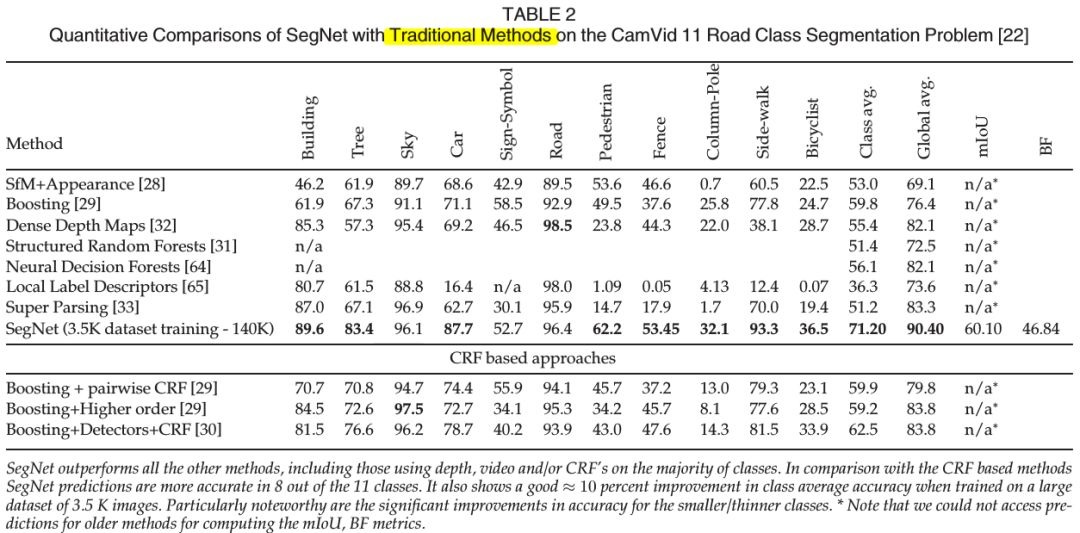
- Traditional method
- DeepLab-LargeFOV
- DeconvNet
1.3. Dataset
- CamVid road scenes
- SUN RGB-D indoor scenes
1.4. Related Work
- Hand Engineered Feature
- DNN
- Random Forest
- Boosting
- Smooth classifier by CRF
- Region Proposal. do not exploit co-occurrence of object or other spatial-context
- RGBD segmentation
- CRF-RNN. using RNN mimic the charp boundary delineation capabilities of CRF; can be appended to any deep segmentation architecture
- Multi-scale. image or feature
- DeconvNet
- DecoupledNet
SegNet is inspired by the unsupervised feature learning architecture proposed by Ranzato.
1.5. Experiments
- Best performance is achieved when encoder feature maps are stored in full
- When memory during inference is constrained, the compressed form (dimensionality reduction, max-pooling indices) can improve performance
- Larger decoder increase performance for a given encoder